
How to Fix “Crawled – Currently Not Indexed” in Google Search Console (Step-by-Step Guide)
Table of Contents
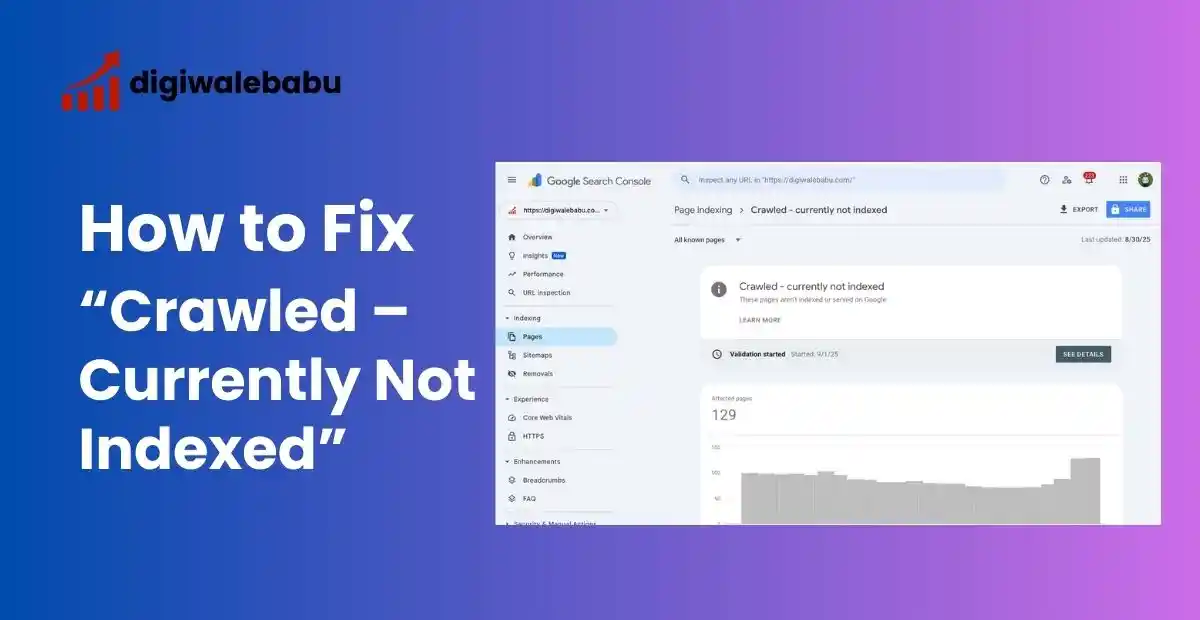
If you’ve been tracking your site in Google Search Console (GSC), you might see some URLs showing up with the status:
“Crawled Currently Not Indexed.”
For many site owners, this can be frustrating. Google has already visited your page, yet it’s still not showing up in search results. Don’t worry — this doesn’t always mean something is broken.
At first, this can feel alarming. You’ve invested time in creating content, Google has already crawled the page, but it’s still not visible in search results.
Don’t panic — this issue is more common than you think and can often be fixed with a systematic approach.
In this detailed guide, I’ll explain:
- What this status actually means
- Why it happens
- A step-by-step action plan to fix it
- And when you don’t need to worry
What Does “Crawled – Currently Not Indexed” Mean?
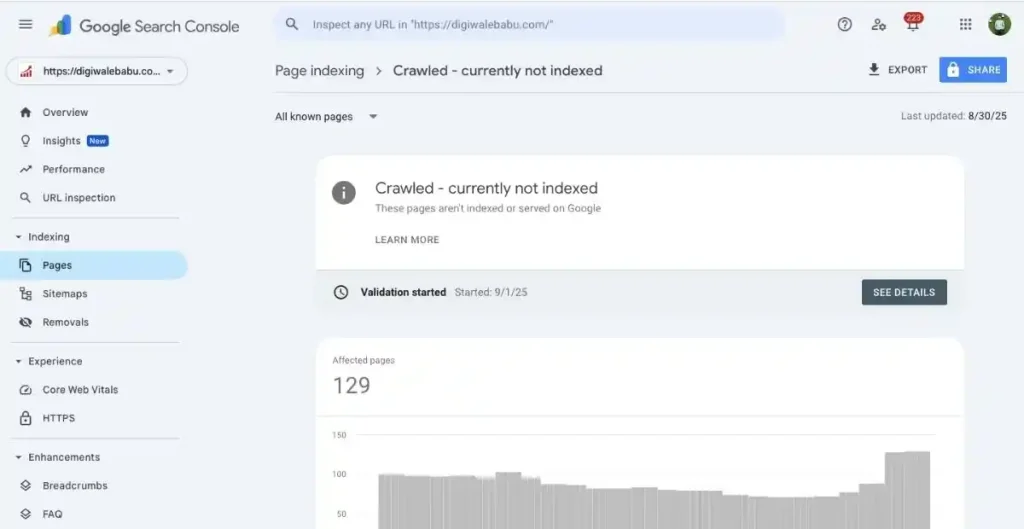
Google has two major steps in its process:
- Crawling – Googlebot visits your site and fetches the content.
- Indexing – Google decides whether to store that content in its database and show it in search results.
When you see “Crawled – Currently Not Indexed”, it means:
- Google successfully crawled your page.
- But Google did not include it in the index (at least for now).
Think of it like a library: The librarian saw your book, skimmed through it, and put it back on the cart — but didn’t place it on the shelf for readers.
Or In simple terms:
- Googlebot has crawled your page (fetched and read it).
- But Google has decided not to index it in search results (at least for now).
Think of it like Google saying: “We’ve seen this page, but we don’t think it’s worth showing in search right now.”
The page might get indexed later, or it might remain excluded until you fix the underlying issues.
Why Does This (Crawled Currently Not Indexed) Happen? (Common Reasons and Quick Fixes)
Here are the most common causes:
1. Low-Quality or Thin Content
What it is: pages that offer little unique information or value — short product blurbs, skeleton category pages, or auto-generated tag pages. Google crawled them, scanned the content, and judged them not worth indexing.
Example: An ecommerce product page with only a 30-word manufacturer description like:
“Plastic tape. Size 10m. Buy now.”
Why Google skips it: the page adds no unique user value beyond what’s already on the site (or the manufacturer’s site). It looks like a low-quality placeholder.
How to detect: low word count, high bounce rate, no organic traffic, GSC shows “Crawled — Currently Not Indexed.”
Fixes (step-by-step):
- Expand the content — add 300+ words that actually help the user: features, use cases, comparisons, maintenance tips, size/fit guidance.
- Add social proof: reviews, ratings, user photos.
- Add structured data (product schema, reviews) to highlight usefulness.
- Include helpful visuals: closeups, lifestyle images, annotated diagrams.
- Add an FAQ block answering real user questions.
Before vs After (micro example):
- Before: “Plastic tape. Size 10m.”
- After: “Heavy-duty double-sided plastic tape — 10m roll. Best for mounting lightweight decor on painted walls without damage. Tested for humidity and heat; holds up to 1.5 kg per strip. User tip: clean surface with isopropyl alcohol before applying.”
When to 301 / canonical / noindex: If improving isn’t possible (e.g., millions of identical SKUs), consider noindex or canonicalize duplicates to a single quality page.
2. Duplicate or Similar Content
What it is: pages that are essentially the same as others — near duplicates across category pages, printered manufacturer copy, or multiple blog posts with the same intro.
Example: Two product pages: /blue-widget and /widget-blue with identical descriptions and only color or URL changed.
Why Google skips it: Google chooses one canonical version (or none) and drops the rest from the index to avoid redundancy.
How to detect: site search shows multiple similar pages, content similarity tools show high overlap, GSC coverage shows many similar URLs with the same status.
Fixes (step-by-step):
- Decide a single primary URL for that content.
- Use a 301 redirect from less-valuable duplicates to the primary page OR add a canonical tag pointing to the primary URL.
- If each variant must exist (color/size), enrich each page with unique content — unique images, variant-specific specs, user reviews per variant.
- For syndicated/mirrored content, request the source to add canonical tags or use syndication-friendly markup.
When to use what:
- If the page should never appear → noindex.
- If duplicates have no independent value → 301 to the main page.
- If duplicates are logically separate but similar → canonical or add unique content.
3. Canonical Tag Confusion
What it is: the page contains a <link rel="canonical"> pointing to another URL (intentionally or by CMS default), so Google chooses the canonical target and skips indexing the current URL.
Example: A product /product?utm=campaign has <link rel="canonical" href="https://example.com/"> (homepage) due to a faulty template. Google will prefer the homepage and not index the product URL.
Why Google skips it: Google follows your canonical instructions; if you point elsewhere, you’re telling Google “index that one instead.”
How to detect: view page source, see canonical tag; URL Inspection in GSC shows canonical chosen different from the URL.
Fixes (step-by-step):
- Inspect the page source for
<link rel="canonical" href="...">. - If wrong, update the template so the canonical is the current page (self-referencing) or the correct canonical target.
<!-- Self canonical --> <link rel="canonical" href="https://example.com/this-page" /> - If multiple versions exist (tracking parameters), canonicalize to the clean URL or use consistent canonical policy.
- Re-run URL Inspection after fixing.
Common CMS pitfall: themes/plugins auto-set canonical to homepage or top category — check templates, not just individual pages.
4. Noindex Tag or Robots Directives
What it is: a meta tag in the page or an HTTP header instructs search engines not to index the page; or robots.txt blocks resources that prevent Google from rendering the content properly.
Example (meta tag): <meta name=”robots” content=”noindex,follow”>
Example (header): X-Robots-Tag: noindex
Why Google skips it: noindex explicitly tells Google not to place the page in the index — crawling can still occur, but indexing is blocked.
How to detect: view page source or check response headers (curl -I <url>). Also inspect robots.txt for blocked CSS/JS that affect rendering.
Fixes (step-by-step):
- Remove
noindexmeta tags orX-Robots-Tagheaders from pages meant to be indexed. - Check robots.txt — do not block vital CSS/JS; blocking them can make Googlebot see an incomplete page.
Example robots snippet to avoid:User-agent: * Disallow: /assets/(This can block CSS/JS if assets are under/assets/.) - After removal, run URL Inspection → request indexing.
Note: use noindex intentionally for internal pages, low-value filters, staging sites; never accidentally.
5. Poor Internal Linking
What it is: important pages have few or no internal links pointing to them (they’re “orphans”), so Google treats them as low priority.
Example: A new detailed guide /how-to-choose-tape exists but is not linked from the blog, sidebar, or product pages — only accessible from the sitemap.
Why Google skips it: Google uses links to understand importance and context. Orphaned pages look unimportant or hidden.
How to detect: crawling tools show zero inbound internal links; site search yields no referring pages; server logs show few internal referrals.
Fixes (step-by-step):
- Add contextual links from relevant, high-traffic pages (blog posts, category pages).
<a href="/how-to-choose-tape">How to choose the right tape for every job</a> - Place the page in navigation, category listings, or a “Related articles” block.
- Use breadcrumbs and footer links only as last resort — contextual links inside content are stronger signals.
- Consider a dedicated internal linking audit and a “link juice” plan: make a handful of pages your hub pages and link out to related articles.
Quick win: add a “Recommended reading” link from two high-traffic posts to this page, then request indexing.
6. Crawl Budget or Priority Issues
What it is: on very large sites, Google doesn’t crawl and index every URL — it prioritizes. Low-value pages may never get indexed if crawl budget is spent on higher-value areas.
Example: A marketplace with millions of faceted search URLs (?color=red&size=10&page=2) where the crawler hits many permutations.
Why Google skips it: duplicate/parameterized URLs waste crawl; Google focuses on the canonical, high-value pages.
How to detect: GSC shows patterns of many similar URLs unindexed; server logs show high crawl on many parameterized URLs.
Fixes (step-by-step):
- Reduce low-value URL creation: avoid creating indexable URLs for every filter/parameter.
- Use canonical tags to point filtered pages to the main category.
- Use
noindex,followfor faceted pages that shouldn’t appear in search but should pass link equity. - Clean up sitemaps: only include priority canonical URLs. Split sitemaps by priority if needed.
- Improve site architecture so important pages are shallow (few clicks from home).
- Monitor server logs to see which pages Google crawls most and adjust accordingly.
When to act: if your site is very large and many useful pages are being missed, prioritization and cleanup are essential.
7. Technical Issues
What it is: server errors, slow responses, blocked resources, heavy client-side rendering without server fallback, or inconsistent status codes can cause Google to crawl but not index.
Example: A page intermittently returns 503 Service Unavailable during peak times; or the page relies on JavaScript to inject the main content but Google can’t render that JS properly.
Why Google skips it: if Googlebot can’t reliably fetch or render the content, it won’t index it.
How to detect:
- Use
curl -I https://example.com/pageto check HTTP status. - Check server logs for spikes in 5xx errors.
- Use site: search and GSC live test to see render results.
Fixes (step-by-step):
- Fix server reliability: resolve 5xx errors, increase capacity or caching.
- Ensure stable 200 responses; avoid flakey redirects.
- Make sure essential CSS/JS aren’t blocked by robots.txt.
- If using heavy JS rendering, implement server-side rendering (SSR) or dynamic rendering so content is available to crawlers.
- Improve performance: reduce TTFB, compress images, use CDN.
- Re-run GSC live test and request indexing after fixes.
Example command to check headers:
curl -I https://example.com/my-page # Look for: HTTP/1.1 200 OK # And absence of: X-Robots-Tag: noindex
Fix “Crawled – Currently Not Indexed” Step-By-Step (do these in order)
Step 1: Inspect the URL in Google Search Console
Paste the URL into URL Inspection → check Live Test and the Indexing section. Note: the live test shows how Google fetches the current page (status code, last crawl, blocked resources, canonical chosen).
Record: last crawl date, crawl response code, canonical URL shown, presence of noindex.
Run a Live Test to see how Googlebot views your page.
Step 2: Check HTTP response & headers
Use https://example.com/page (or an online header checker) to verify response code (200, 301, 404, 5xx) and check for X-Robots-Tag.
If the page sometimes returns 5xx or inconsistent codes, fix server issues — intermittent 5xx responses can cause Google to avoid indexing.
- Confirm the page returns a 200 OK response.
- Avoid redirects (301/302), 404s, or server errors (5xx).
- Ensure the page loads quickly and resources (JS, CSS, images) are not blocked.
If Google can’t fully render the page, it may decide to skip indexing
Step 3 — Review Meta Tags & Robots Rules
These are explicit instructions placed on a page that tell Google whether it’s allowed to show that page in search results. A noindex instruction means “don’t put this page on the shelf,” even if Google looked at it.
How to check (easy, no-code):
- Open the page in your browser.
- Right-click → View Page Source (or press
Ctrl+U/Cmd+U). - Search (Ctrl/Cmd+F) for
noindexorrobots. If you see<meta name="robots" content="noindex">, that page is telling Google not to index it. - To check headers (if you’re comfortable): open browser DevTools → Network tab → reload the page → click the main document and look at Response Headers for
X-Robots-Tag.
What it looks like (example):
<meta name="robots" content="noindex, nofollow">
or in a response header: X-Robots-Tag: noindexWhy this is important: If noindex is present, Google will not show the page in search results even if it crawled it.
Simple fix (non-technical steps):
- If you find
noindexand you do want the page listed in search, remove it. - If you don’t manage the website yourself, copy this message and send it to your developer or support:
What to send your developer: Hi — Google Search Console shows the page at https://example.com/page as “Crawled — Currently Not Indexed.” I noticed a noindex directive. Please remove any noindex meta tag or X-Robots-Tag: noindex header for this URL so the page can be indexed. Thanks!
When noindex is intentional: keep it for private pages (staging, admin, thank-you pages). Don’t remove it in those cases.
Step 4: Verify Canonical Tags
A canonical tag is like putting a Post-it on one version of a page that says “this is the official copy.” If your page points that Post-it to another page, Google will index the other page instead.
How to check (easy):
- View Page Source again (
Ctrl/Cmd+U) and search forrel="canonical". - You’ll see something like:
<link rel="canonical" href="https://example.com/main-version-of-page" />Common problem (example):
- You have
https://example.com/productandhttps://example.com/product?color=red. - If
product?color=redhas<link rel="canonical" href="https://example.com/product">, Google will prefer/productand may not index/product?color=red.
Why this matters: If the canonical points away from the URL you checked, Google assumes the other URL is the one to index.
Simple fixes you can request:
- If the page should rank on its own, canonicalize to itself (self-referential):
<link rel="canonical" href="https://example.com/this-page" />- If it’s a variant (filters, tracking tags), canonicalize to the main version or decide to merge/redirect.
What to send your developer: Hi — can you check the canonical tag for https://example.com/page? It currently points to https://example.com/other-page (or to the homepage). Please set the canonical to itself if this page should be indexed, or explain which URL you intend Google to treat as the primary version. Thanks!
Step 5: Improve Content Quality
Google wants pages that help people. If a page is short, shallow, or repeats what other pages say, Google ignores it. Fixing content is the single biggest win.
How to tell if content is “thin”:
- Page has only 1–2 short sentences.
- It copies manufacturer descriptions, press releases, or other pages.
- It doesn’t answer questions a visitor would have.
Concrete improvements (recipe you can follow):
- Add practical details — features, measurements, material, differences vs alternatives.
- Show how to use it — a short “How to” or “Tips” section.
- Add user proof — reviews, ratings, photos from customers.
- Put an FAQ — 3–6 short Q&As for common questions.
- Add visual help — at least one clear product image or a diagram.
- Add short, helpful headings and break content into bite-sized chunks.
Before / After micro example
Before: “Plastic tape. 10m. Buy now.”
After: “Heavy-duty 10m plastic tape — ideal for mounting posters and lightweight frames. Tip: wipe the surface with alcohol before applying. Holds up to 1.2 kg when used per instructions. Customer review: ‘Held my poster for 6 months in humid kitchen!’”
Structured data (simple note): think of it as tiny labels that help Google understand the page (e.g., “this is a product” or “this page contains FAQs”). Ask your developer or SEO tool to add them — they boost clarity.
What to send your content writer / developer: Please expand https://example.com/page with: a product overview, 3 usage tips, 3 FAQs, at least one customer photo, and structured data for product/FAQ. Aim for helpful, unique copy (not the manufacturer text).
Step 6: Strengthen Internal Linking
Internal links are the site’s signposts. If no pages link to a page, Google treats it like a back-office file — less important.
How to check (quick):
- Search your site (e.g., use the CMS search) for the page URL or title to see if it’s linked from other content.
- Or browse obvious places: related articles, blog posts, category pages.
Easy ways to add links:
- Add a link from a relevant blog post: “Learn more in our product guide.”
- Add the page to a category or product listing.
- Use “Related articles” or “You might also like” blocks.
Good anchor text example:
- Weak: “click here”
- Strong: “how to choose heavy-duty tape” (uses descriptive keywords and tells Google what the linked page is about)
What to tell your content/editor
Please add two contextual links to
https://example.com/pagefrom existing high-traffic posts or the relevant category page. Use descriptive anchor text (e.g., “heavy-duty 10m tape” or “how to mount posters without damage”).
Step 7: Ensure It’s in Your Sitemap
A sitemap is a map of your site for Google. Putting a page in the sitemap is like adding it to the library catalog — it helps Google find and prioritize it.
How to check (very quick):
- Visit
https://example.com/sitemap.xmlin your browser and search for the page URL. - If it’s missing, that’s an easy fix.
How to add / submit (if you don’t manage the site): Tell your developer or site manager to add the URL to the sitemap and then re-submit the sitemap in Google Search Console → Sitemaps → Add sitemap.
What to tell your developer: Please include https://example.com/page in sitemap.xml and re-submit the sitemap to Google Search Console. If sitemaps are auto-generated, ensure the page is not excluded by rule.
Step 8: Optimize User Experience (UX)
A page must behave well on phones and load quickly. If it’s slow, broken, or jumps around, Google may treat it as low-quality.
Simple tests you can do (no developer needed):
- Open the page on your phone. Does it look OK? Are buttons tappable and text readable?
- Does the main content appear quickly or does it take a long time?
- Do images/loadables shift around as the page loads? (If text/buttons move when images load — that’s annoying for users.)
User-friendly fixes to ask for:
- Compress large images so they load faster.
- Avoid intrusive pop-ups that cover content.
- Ensure buttons and links work and aren’t broken.
- Make sure the page layout doesn’t shift as things load (reduce “jumping”).
Core Web Vitals explained in one line each:
- Loading (LCP): how quickly the main content loads.
- Interactivity (INP/FID): how quickly the page responds to your first interaction.
- Stability (CLS): how much layout jumps around while loading.
What to tell your developer / web team: Please check this page for mobile usability and Core Web Vitals. Prioritize reducing image sizes, enabling browser caching, and removing scripts that block rendering. Also fix any broken links or console errors.
Step 9: Request Indexing
After you’ve fixed problems, you can politely ask Google to take another look sooner rather than later.
How to do it (step-by-step):
- Open Google Search Console.
- Use URL Inspection → paste the exact page URL → press Enter.
- If the page is now good, click Request Indexing.
Important note: this is a nudge, not a magic button. Google may re-crawl the page quickly, but indexing is still up to its systems.
What to expect: Sometimes Google indexes in hours, sometimes it’s a few days. If issues remain, the status won’t change.
Step 10: Monitor and Iterate
Fixing is rarely one-and-done. You watch, tweak, and repeat until Google is happy.
What to watch (simple):
- Re-check the URL in Google Search Console after a few days. Has the status changed?
- Look at your website analytics: did traffic to that page start to appear?
- If still not indexed after your fixes and a few checks, consider whether the page should exist at all or be merged with a stronger page.
Decisions to make if it’s still not indexed:
- Merge: Combine weak pages with a stronger, related page and 301-redirect the weak ones.
- Noindex intentionally: If the page is not meant for search (internal tools, staging), mark it
noindex. - Keep improving: Add more unique content or increase internal links and ask again.
Simple daily/weekly monitoring checklist
- Day 0: Fixes applied → Request Indexing.
- Day 3–7: Check GSC URL status.
- Week 2–3: If unchanged, re-evaluate content value or merge.
When Should You Not Worry About Indexing?
Many people panic when they see that some pages on their website are not indexed by Google. But here’s the truth: not every page needs to be indexed.
Google doesn’t want to waste space in its search results on pages that don’t help users.
Let’s break this down with real-life examples:
1. Tag Pages
Example: Imagine you run a blog about cooking. You create tags like “Breakfast,” “Dinner,” or “Quick Recipes.”
- A “Breakfast” tag page simply shows a list of blog posts with that tag.
- It doesn’t add any unique value beyond what’s already on the individual recipe pages.
In this case, it’s okay if Google doesn’t index your “Breakfast” tag page. The real value lies in your actual recipes, not the tag archive.
2. Duplicate Product Filters
Example: If you own an online clothing store, you may have filter pages like:
- example.com/shirts?color=red
- example.com/shirts?color=blue
- example.com/shirts?color=red&size=medium
These filter pages are useful for customers browsing your site, but they’re not useful for Google. They usually just show the same shirts, shuffled in different ways.
It’s fine if these pages remain unindexed, because they don’t provide unique content that deserves to appear on Google.
3. Internal-Only Content
Example: Suppose you have a private page that lists your company’s internal policies, employee forms, or test pages used by your web developer.
- These are not meant for the public.
- Even if they’re accessible through a link, they don’t provide any value to a searcher on Google.
You should keep these pages unindexed on purpose. That way, Google focuses only on the content that matters to your customers.
The Key Takeaway:
Don’t stress if some of your pages aren’t indexed. Instead of trying to get every single page into Google, focus on the ones that:
- Provide unique, valuable information
- Solve a problem or answer a question
- Are meant for your audience
Think of Google indexing like a library catalog: not every scrap of paper goes in; only the important books and resources that people will actually use.
Most Of The Bloggers Have Doubts On “Crawled – Currently Not Indexed” – Here are the Q&A
What does “Crawled – Currently Not Indexed” mean in Google Search Console?
It means Google has crawled your page but decided not to include it in its search index yet. The page exists, but it won’t show up in search results.
Why is my page marked as “Crawled – Currently Not Indexed”?
This usually happens due to thin or duplicate content, low-quality pages, lack of backlinks, or when Google doesn’t see enough value to index the page right away.
Is “Crawled – Currently Not Indexed” an error?
No, it’s not an error. It simply shows that Google is being selective. Your website is still functioning fine.
How can I fix “Crawled – Currently Not Indexed”?
Improve your content quality, add strong internal links, ensure technical SEO is correct, and make the page valuable for users.
Should I worry about all unindexed pages?
Not necessarily. Pages like tag archives, duplicate filters, or internal-only pages don’t need indexing. Focus on your most important content first.
How long does it take for Google to index a page?
It can take anywhere from a few days to several weeks. High-quality, well-linked pages usually get indexed faster.
Can I force Google to index my page?
You can request indexing in Google Search Console, but if the page lacks value, Google may still skip it.
Will my traffic be affected if a page is not indexed?
Yes, because only indexed pages can appear in search results. That’s why important pages should be optimized for indexing.
Final Thoughts
Seeing the message “Crawled – Currently Not Indexed” in Google Search Console can feel alarming, but it’s important to remember—it doesn’t mean your website is broken. It simply means Google visited your page, looked at the content, and decided not to add it to the search index yet.
Think of it like this: Google’s index is a giant library. Every time your page is crawled, Google is deciding whether it deserves a spot on the shelf. If your page isn’t added, it doesn’t mean it’s bad—it just means Google doesn’t think it’s useful or unique enough compared to other books already on the shelf.
The good news? You can influence that decision.
What you should do:
- Fix technical issues: Make sure there are no roadblocks stopping Google from properly understanding your page. For example, if your site loads slowly, has broken links, or uses messy code, it’s like handing Google a book with missing pages—it won’t make it to the library shelf.
- Improve content quality: Pages with thin or duplicate content usually don’t get indexed. Add more detail, provide unique insights, or answer common questions. For example, if you sell a product and only list specs, Google might skip it. But if you add customer FAQs, usage tips, or comparison guides, it suddenly becomes valuable.
- Strengthen internal linking and signals: Google needs clues about which pages on your site matter most. Linking from high-traffic or important pages to the ones you want indexed is like shining a spotlight on them. For instance, if you’ve published a helpful guide, link to it from your homepage or related blog posts.
The bigger picture:
Not every single page has to be indexed. Some pages—like duplicate filters, tag pages, or private internal content—don’t bring value to search users. And that’s perfectly fine.
Instead of chasing every URL, put your energy into making your most important content irresistible for indexing. Over time, as Google sees that your site consistently provides value, it will naturally index more pages.
So, don’t panic when you see “Crawled – Currently Not Indexed.” Use it as a gentle nudge to improve your website step by step. With patience and the right strategy, your valuable pages will earn their spot on Google’s shelf.